Société et territoires Temps de lecture 1 min
Des robots qui arrivent à lire (presque) tout seuls
Publié le 24 octobre 2019

Si vous lisez cet article, il y a fort à parier que vous êtes un être humain. Le robot ou le simple programme informatique qui comprendra ce texte n’est pas encore né. Rien d’étonnant à cela puisque l’apprentissage de la lecture demande déjà des années à un humain.
Alors bien sûr, n’importe quel ordinateur peut aujourd’hui parcourir bien plus rapidement qu’un humain une quantité astronomique de textes en un instant. Mais même nos meilleurs robots peinent encore à comprendre des informations parfois triviales. Pour un robot, comprendre cet article équivaut pour nous à déchiffrer pour la première fois de la langue elfique.

Exemple de langue elfique : deux vers du « Namárië », un poème présent dans le Seigneur des Anneaux de J.R.R. TolkienWikipedia
Or l’humanité a produit et continue de produire des montagnes de textes. Sans l’assistance de robots-lecteurs, la majorité de leur contenu ne sera malheureusement jamais utilisée, quand bien même certaines d’entre elles permettraient de répondre à de grands défis sociétaux, médicaux ou environnementaux par exemple.
Des robots capables d’extraire
les informations
Pour exploiter cette infinie richesse, des robots qui se contentent de nous rapporter des documents intéressants, comme nos moteurs de recherches sur Internet, ne suffisent plus. Nous avons besoin de robots capables d’extraire directement de grandes quantités d’informations potentiellement d’intérêt.
Prenons un exemple. Imaginons que vous vous interrogiez sur les lignées mythologiques des dieux gréco-romains. Sur Wikipedia, cette connaissance est disséminée dans de très nombreux documents. Plutôt que de les lire nous-mêmes, l’idéal serait qu’un robot nous construise automatiquement tous les arbres généalogiques de ces dieux, dans un format que nous pourrions facilement manipuler par la suite.
Pour qu’il remplisse sa mission, au moins en partie, il devrait être capable d’une part d’identifier les noms de personnages sur toutes les pages Wikipedia ; ensuite de détecter lorsqu’une relation de parenté directe est exprimée.
Pour un robot, répondre à un tel objectif d’extraction d’information s’assimilerait à de la compréhension, et le rendrait apte à répondre facilement à de nombreuses questions, par exemple : qui sont les petits-enfants du dieu Zeus ?
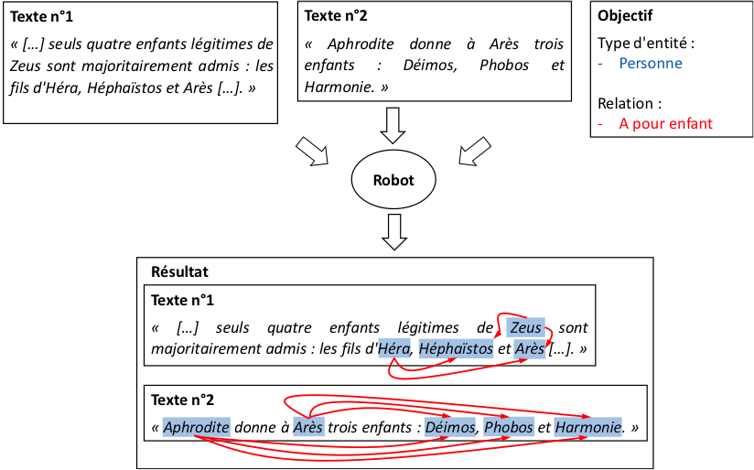
Exemple possible d’extraction d’information. À partir de deux documents textuels et d’information sur l’objectif d’extraction, le robot identifie les entités d’intérêts et les relations qu’elles partagent. Ainsi, il peut reconstruire ici une partie de l’arbre généalogique du dieu grec Zeus. Auteur/Wikipedia.
Dans l’exemple précédent, les dieux gréco-romains représentent ce que l’on appelle des entités. Chacune peut être mentionnée dans du texte par un mot (ex : « Arès ») ou par plusieurs (« dieu de la guerre »). Les langues permettent d’ailleurs d’exprimer une entité de très nombreuses manières différentes. On se limite souvent à identifier leur type (ex : dieu gréco-romain, ou personnage mythologique), plutôt que leurs mentions. Reconnaître que des mots désignent un type d’entité – par exemple, des personnes – est ce que l’on nomme la reconnaissance d’entité.
Comprendre une relation entre des entités identifiées, comme celle de parenté, est ce que l’on nomme l’extraction de relation. Ce sont les deux tâches principales communément effectuées par un programme d’extraction d’information.
Une multitude de façons de nommer
les choses
Lorsque notre robot réussit à extraire que « Zeus » a pour enfant « Arès », puis dans une autre phrase que « Arès » a pour enfant « Harmonie », il est simple de comprendre que l’on parle de la même entité. Mais ce n’est pas toujours aussi simple : « Arès » et « dieu de la guerre » représentent bien une même et unique entité.
Même si notre robot parvenait à comprendre que ces deux expressions désignent des personnes, il ne saurait a priori pas que ce sont les mêmes. Dès lors, de l’information utile est perdue et il lui devient impossible de saisir qu’Harmonie est la petite-fille de Zeus.
Une étape supplémentaire est donc nécessaire : la normalisation d’entité. Elle consiste à relier toutes les différentes mentions d’une même entité à une unique référence. Dans le cas qui nous intéresse, la référence sera le dieu Arès, et normalisera les expressions « Arès », « dieu de la guerre », et tous les autres termes qui pourraient désigner cette divinité. Si des méthodes de normalisations existent déjà, elles sont encore peu performantes, se trompent et manquent beaucoup d’informations. En pratique, aucune méthode ne fonctionne à 100 % – même l’humain n’est pas infaillible en la matière.
Jusqu’à il y a quelques années, la principale solution utilisée dans les programmes pour résoudre ce problème était de regarder si une référence et une mention partageaient une forte similarité au niveau de leur séquence de caractères. On comprend bien que les mots « chienne » et « chiens » ressemblent plus au mot « chien » qu’au mot « poisson ».
Malheureusement, cela ne fonctionne pas lorsque la périphrase pour désigner « Arès » est « dieu de la guerre »… Or, les langues naturelles possèdent une infinité de variations de ce genre pour exprimer un même type d’entité. Imaginez que l’on ait seulement une référence « chien », il faudra réussir à bien normaliser ses synonymes comme « toutou », mais aussi ses hyponymes comme « labrador », « doberman », et tous les autres noms de race de chien ! Sans parler des expressions plus complexes telles que « le meilleur ami de l’homme » !
Le point commun entre un os et un bâton
Plutôt que d’utiliser les séquences de caractères des mots, on aimerait pouvoir se rapprocher directement de leur sens. Si l’on était en mesure de savoir que « Arès » et « dieu de la guerre » possédaient un sens très proche, alors il serait beaucoup plus simple pour un programme de les normaliser correctement. Pour cela, l’approche la plus courante est d’étudier, non pas directement les mots que l’on voudrait identifier, mais plutôt les autres termes qui apparaissent fréquemment avec eux dans des phrases.
Par exemple, si je vous donne la phrase « Un chien ronge un schtroumpf », qu’est-ce qu’un « schtroumpf » ici ? J’imagine que parmi les réponses possibles, vous avez pensé à un « os ». Sans doute parce qu’après des années d’utilisation de la langue française, vous avez fréquemment vu le mot « os » apparaître avec les mots « chien » et « ronge », plus qu’avec la plupart d’autres termes.
Et si je vous disais qu’en réalité, j’avais remplacé non pas le mot « os », mais le mot « bâton » par « schtroumpf ». Que peut-on en déduire des liens entre ces deux mots ? L’hypothèse la plus courante est d’en déduire que ces mots partagent un sens similaire comme ici le fait d’être des objets rongeables par des chiens. Et plus deux mots apparaissent dans des phrases similaires, plus ils partageront des sens proches. En conséquence, en parcourant de grandes quantités de phrases, nos robots sont capables de mieux appréhender le sens des mots et cela quelle que soit leur forme.
Grâce à cela, il est facile de comprendre que « chien » et « toutou » ont un sens très proche, et que « chat » et « char » pas du tout. À peu près de la même façon, nos robots réussiront à comprendre que « Arès » et « dieu de la guerre » sont la même entité, et ainsi bien reconstruire notre arbre généalogique.

Que se passe-t-il dans le cortex quand on apprend à lire ? cheriejoyful on Visual Hunt, CC BY-NC-ND
Des robots plus performants,
mais encore limités
Pour autant, nos robots sont-ils capables de comprendre aussi bien que nous la langue écrite ? Au risque de vous décevoir, je crains que non. De très nombreux obstacles demeurent, qui sont au cœur des activités de recherche de nombreux scientifiques – comme moi. Pour citer quelques exemples : les expressions ambiguës (ex : « avocat », métier ou fruit ?), les mots rares, l’ironie, les coréférences (ex : « C’est mon chien. Il ronge un os. » Est-ce le chien qui ronge un os ou seulement « il » ?)… Tous ces obstacles s’entrecroisent en permanence, rendant la compréhension de la langue bien difficile.
Les travaux récents les plus prometteurs se fondent sur l’apprentissage automatique, dont les réseaux de neurones sont l’exemple le plus populaire. Ce sont par exemple eux qui ont permis au programme AlphaGo de battre un des meilleurs joueurs de Go mondiaux en 2016, et ils sont de plus en plus utilisés à travers le monde. Plutôt que d’étudier la forme des mots, un robot qui aurait recours à l’apprentissage automatique apprendrait à normaliser des mentions à partir d’exemples de mentions déjà normalisées par des humains. Néanmoins, pour ce problème de normalisation, les réseaux de neurones classiques semblent encore limités.
Les robots qui l’utilisent ont notamment besoin de très nombreuses explications avant de pouvoir correctement répondre à un problème. Parfois, c’est presque comme s’il fallait leur donner nous-mêmes toutes les questions et réponses qu’il y aura à l’examen final ! Or, dans de nombreux cas, dans le domaine biomédical par exemple, tout leur expliquer aussi finement représenterait un travail démentiel !
Sur ce point, comparés aux robots des autres classes dans le monde, mes robots sont d’excellents élèves en normalisation : ils savent apprendre avec peu d’explications, et l’ont démontré en obtenant les meilleures notes lors d’un challenge scientifique international.
S’ils sont si performants, c’est que je leur donne les connaissances basiques du domaine sur lequel ils doivent travailler. S’ils doivent normaliser les mentions d’animaux, je leur enseigne que les chiens et les chats sont des mammifères, et qu’un mammifère est un animal. Ces acquis leur permettent de ne pas partir de zéro, d’appréhender le domaine, et de mieux se concentrer sur leur tâche.
Jusqu’ici, ils savent seulement normaliser, et je commence à les former à résoudre d’autres tâches. Il me reste donc encore beaucoup à leur enseigner, mais chaque jour la science-fiction devient un peu plus réalité.
|
Arnaud Ferré, Docteur en intelligence artificielle appliquée aux sciences du vivant, Université Paris-Saclay Cet article est republié à partir de The Conversation sous licence Creative Commons. Lire l’article original. |