Temps de lecture 5 min
Embarquement pour le web sémantique !
Publié le 03 mai 2019

Qu’est-ce que le web sémantique par rapport au web lui-même ?
Danaï Symeonidou : Le web sémantique est structuré, interprétable. Il a pour but de transformer le web d’aujourd’hui où l’on a beaucoup de texte mais non structuré et, par là, non interprétable par les machines.
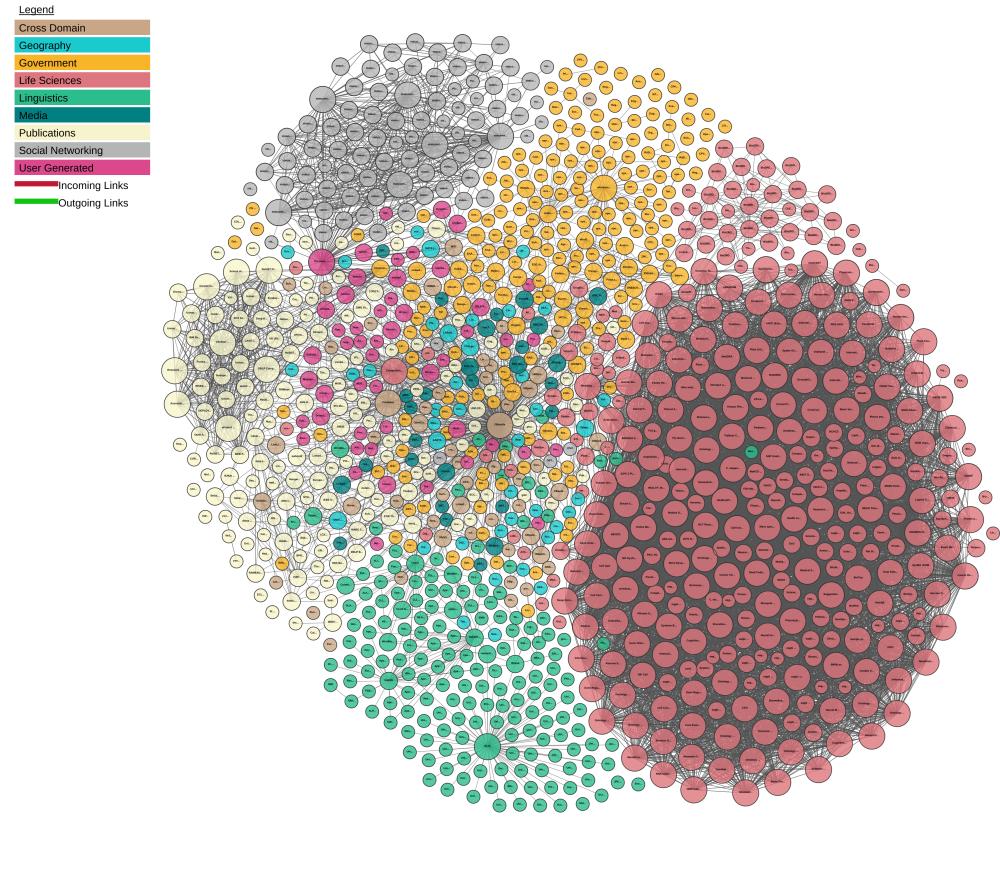
Beaucoup de personnes travaillent à former les bases de connaissance. Par exemple, DBpedia transforme les données de Wikipédia en données structurées. Ces données sont publiées et mises à disposition sur le Linked Open Data Cloud (Figure1). Il s’agit d’un nuage où les gens, y compris l’Inra, publient leurs données qui sont ainsi à disposition sur le web. Chaque nœud dans ce nuage correspond à un jeu de données déjà disponible sur le Cloud. J’ai travaillé sur des données comme celles-ci, déjà transformées en données structurées.
Comment structure-t-on les données ?
Danaï : Je travaille sur des données structurées qui viennent du web : les données RDF. Ce framework permet de structurer les données, de les interpréter et les rendre interprétables par d’autres. Les données de DBpedia sont structurées de la même manière, avec des triplets « sujet,propriété,valeur ». Par exemple : <PersonneN°32,Prénom,Danai> ou <PlanteN°1610,Variété,Gariguette>. Les machines sont ainsi capables d’interpréter l’information. Et derrière ces données structurées, on utilise des ontologies.
Qu’est-ce qu’une ontologie ?
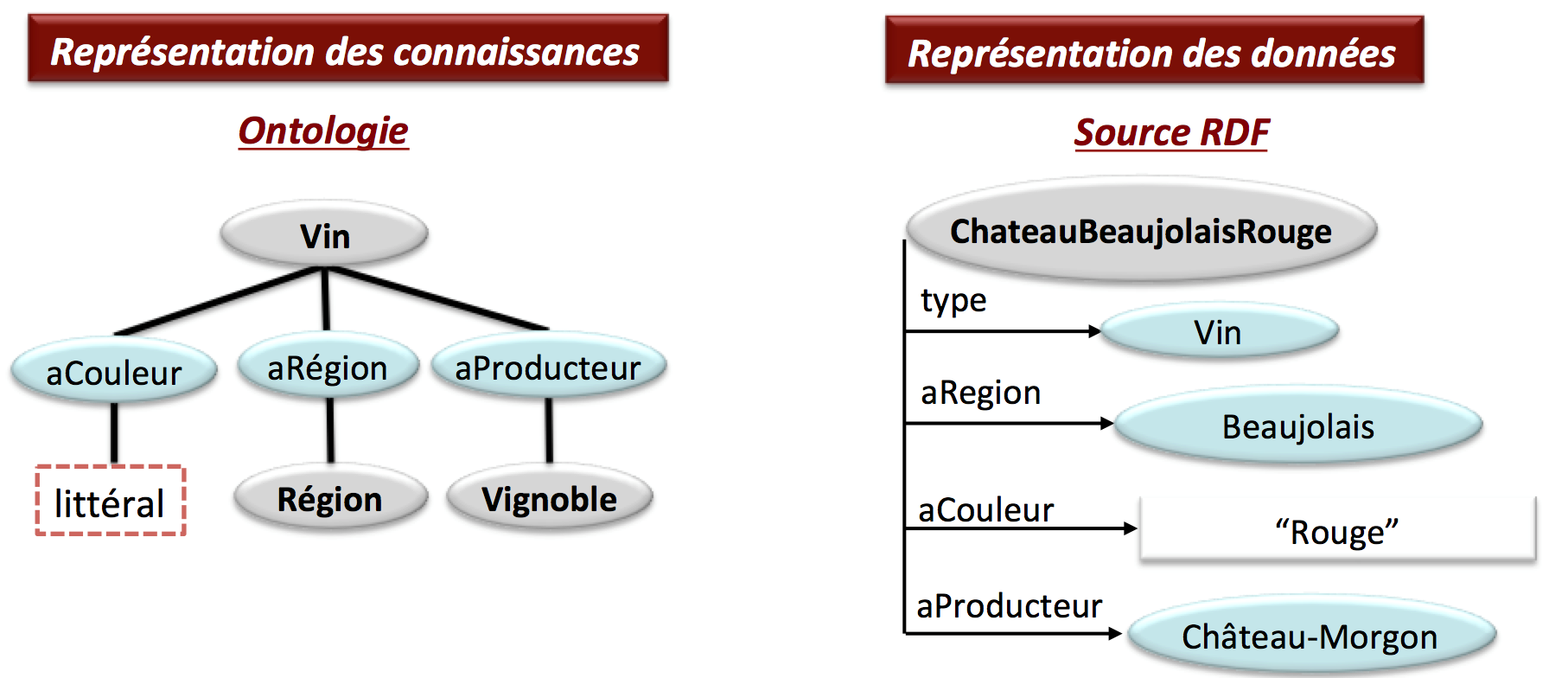
Danaï : Tu peux penser une ontologie comme un schéma qui permet de décrire les données. C’est l’information abstraite d’un objet. On a deux éléments principaux : les classes (personne, vin, vignoble, vélo etc.) et les propriétés (aRégion, aCouleur, etc.). Un vin a une couleur et il est produit dans un vignoble comme nous pouvons le voir dans la Figure 2. Les nœuds gris y représentent les classes de l'ontologie et les nœuds bleus leurs propriétés. Dans la deuxième partie de cette figure on voit un exemple de données conformes à cette ontologie : le ChateauBeaujolaisRouge est un vin rouge élaboré dans le Beaujolais par Château-Morgon. Une ontologie est une représentation des connaissances qui permet de comprendre un domaine thématique, d'avoir un vocabulaire uniforme et raisonner sur les données. Par exemple, une ontologie va dire qu'une personne ne peut être mariée qu’avec une autre personne. Si dans nos données une personne est mariée avec un animal, c’est qu’il y a un souci !
L’ontologie, c’est donc comme les règles de grammaire des données ?
Danaï : Exactement, c’est une structure générique qui permet d’avoir une hiérarchie et des corrélations entre les données. Par exemple, on peut définir dans une ontologie qu'un chercheur est aussi une personne. Prenons maintenant un jeu de données où il existe un chercheur, par exemple désigné par <PersonN°32,type,Chercheur> et on sait par l’ontologie que chaque chercheur est aussi une personne alors on peut déduire que <PersonN°32,type,Personne>.
Qu’est-ce que le liage des données ?
Danaï : Le liage des données, c’est l’intégration des données. Prenons une base de données, c’est-à-dire un endroit où il y a beaucoup de données, par exemple décrivant plusieurs personnes, tel que l’annuaire Inra. Imaginons maintenant un instant que nous voulons lier ces données à celles des bases de données des impôts et à celles d’Ameli pour en relier tous les services. La découverte de liens entre les instances qui font référence au même objet du monde réel est appelé liage de données.
La Figure 3 illustre un exemple, issu de l'oenologie, où deux sources de données différentes ont un vin en commun. Parvenir à trouver que ChâteauBeaujolaisRouge et Beaujolais_Red désignent le même vin s’appelle liage de données.
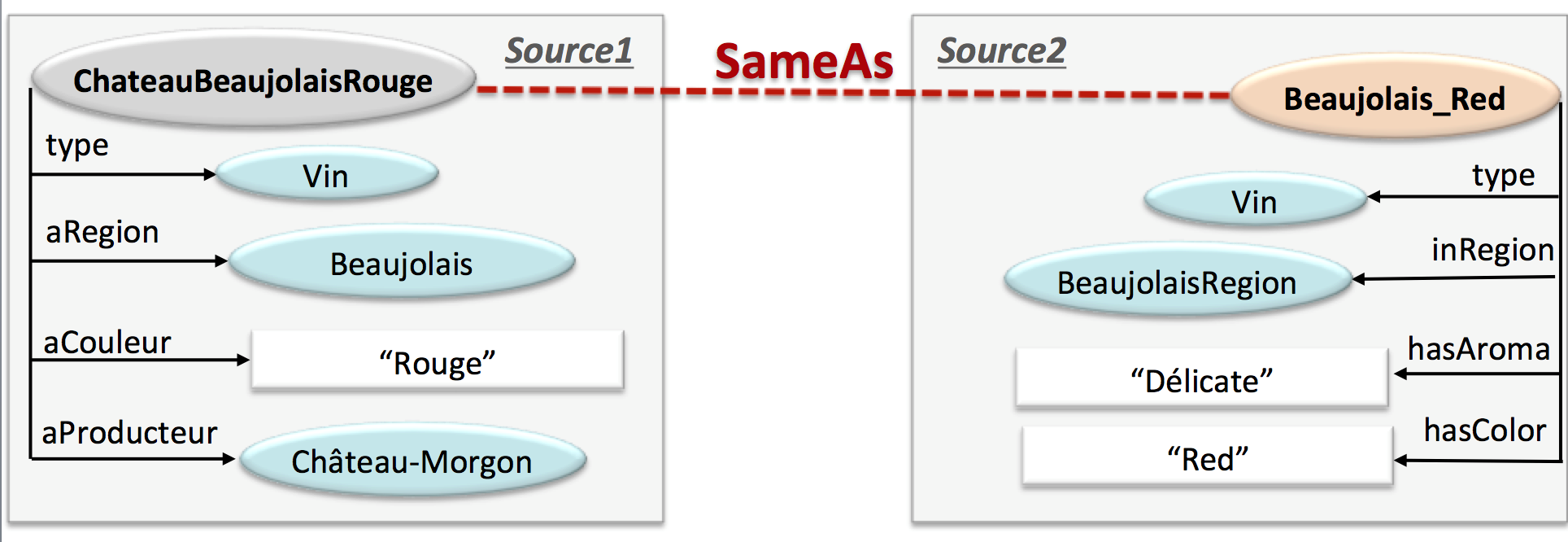
Pour le faire, manuellement c’est impossible, on a besoin d’un identifiant. Si nous revenons à l'exemple des personnes, le numéro de sécurité sociale est un identifiant : si deux enregistrements ont le même, c’est qu’ils se rapportent à la même personne. Mais, la plupart du temps, les identifiants sont inconnus : mon travail consiste à proposer des algorithmes qui les découvrent de façon efficace. Je prends un ensemble de caractéristiques, par exemple nom, prénom et date de naissance, je vais alors pouvoir distinguer toutes les personnes d'une base et comparer à une autre base de connaissances. En combinant nom, prénom, adresse, je vais également pouvoir retrouver les mêmes personnes. C’est cela qu’on appelle des « clés ».
Qu’est-ce qu’une clé ?
Danaï : Les clés sont des ensembles de propriétés qui nous permettent d’identifier de façon unique chaque élément dans un jeu de données. Dans un jeu de données qui comprend 5 propriétés, le nombre de combinaisons possibles entre elles est (25-1 = 31). Nom tout seul, nom avec adresse, nom avec adresse et date de naissance, etc. Il faut tout essayer et déceler ce qui est pertinent avec l’aide des algorithmes que nous élaborons. On travaille sur du web, donc sur de gros volumes de données hétérogènes avec des caractéristiques difficiles à traiter. L’informatique permet de calculer de façon efficace quelque chose que l’humain ne peut pas faire à la main.
Données symboliques, données numériques : quelles différences ?
Danaï : Les données symboliques sont basées sur du texte, tandis que les données numériques concernent les nombres. Il y a une différence de traitement. Par exemple, lorsqu'on mesure les pH de plusieurs éléments, on sait que celui dont le pH est de 3,47 est plus proche de celui mesuré à 3,49 que d'un troisième mesuré à 9,2. En revanche, ce n'est pas parce qu'elles s'appellent "Royal gala" et "Reine des reinettes" que deux variétés de pommes sont plus proches entre elles qu'elles ne le sont d'une troisième nommée "Golden" ! Avec des données symboliques, ce n’est pas l’ordre des lettres qui nous renseigne sur la plus ou moins grande proximité de ces variétés de pommes.
Qu’est-ce qu’une fonction ?
Danaï : Par exemple surface = largeur x longueur est une fonction. Il y a des fonctions plus difficiles, avec des puissances, etc. À l’Inra, je travaille beaucoup sur des données numériques, il faut découvrir s’il y a des fonctions dans les données. Pour cela, je suis allée à l'Insight Center for Data Analytics, à Cork, où il y a des spécialistes de l’analyse des données. En particulier, j’y ai travaillé avec un spécialiste des algorithmes « génétiques ».
Qu’est-ce qu’un algorithme « génétique » ?
Danaï : On fait l’analogie avec la nature, qui à partir de deux parents, peut construire un hybride qui aura de meilleures qualités que ses deux parents. Ainsi, on essaie de mélanger des hybrides candidats pour obtenir des hybrides de meilleure qualité. On a des scores pour dire : celui-là est meilleur, on le garde, celui-là n’est pas bon, on le jette. Au début on fait des fonctions aléatoires par exemple 3 fois longueur + 4 fois largeur = surface et on voit si en les appliquant à nos données, elles se vérifient ou pas… Je fais comme cela une dizaine de fonctions aléatoires et je calcule le score de chacune. Je prends le top 3 que j’essaie d’améliorer. Chaque fonction est un « chromosome » et tous les chromosomes ensemble forment une population. Je peux prendre quelques éléments de chaque fonction ou chromosome - on appelle cela des « gènes » - et les combiner pour voir si je peux avoir un meilleur score. Pourquoi procéder ainsi ? Parce qu’il ne nous est pas possible d’explorer tous les cas (fonctions) possibles. Les « algorithmes génétiques » permettent d’en explorer une partie et de nous guider vers les bonnes réponses. On prend les meilleurs et on essaie à chaque fois de faire encore meilleur. Au bout d’un certain score, on peut décider d’arrêter ou pas.
Quelles applications ?
Danaï : Nous avons un exemple en cours sur des données agronomiques venant de l’unité Inra Science pour l’œnologie (SPO) ; il s'agissait de données simulées pour pouvoir en vérifier la validité. J’ai aussi travaillé sur des données numériques sur les caractéristiques de vins mais qui ne venaient pas de l’Inra. Nous sommes en train de préparer l’application à de vraies données expérimentales.

Sa toile est le « web sémantique ». D. Symeonidou est chercheuse en intelligence artificielle à l’unité Mathématiques, informatique et statistiques pour l'environnement et l'agronomie - centre INRAE Occitanie-Montpellier. Lire son portrait...