Agroecology Reading time 4 min
Dominant and recessive gene expression, chapter Two: the molecular mechanism for dominance
Published on 17 December 2014

As is often the case in other fields, although rarely in evolutionary biology, theoretical predictions looked further ahead than what experiments had proven. One such example is the prediction of dominance modifiers, a genetic element specific to an allele that determines whether it is dominant or recessive. This hypothesis, offered as early in 1930, was only proven through experiments in 2010.
Dominance modifiers do exist: theoretical predictions are finally proven…
In 2010, a Japanese team (1) showed that the dominance modifier is a small RNA. The RNA is encoded by a portion of the dominant allele’s sequence. It recognises a specific sequence on the recessive allele and blocks its expression. This mechanism was demonstrated on cabbage for a self-incompatible allele pair encoding for the pollen determinant (the “key”; see Chapter Two) by using bioinformatics and functional validation. This research was the first time a dominance modifier – predicted by Wright in the 1930s (see Chapter Two) – was shown to exist.
... but a basic explanation proves elusive
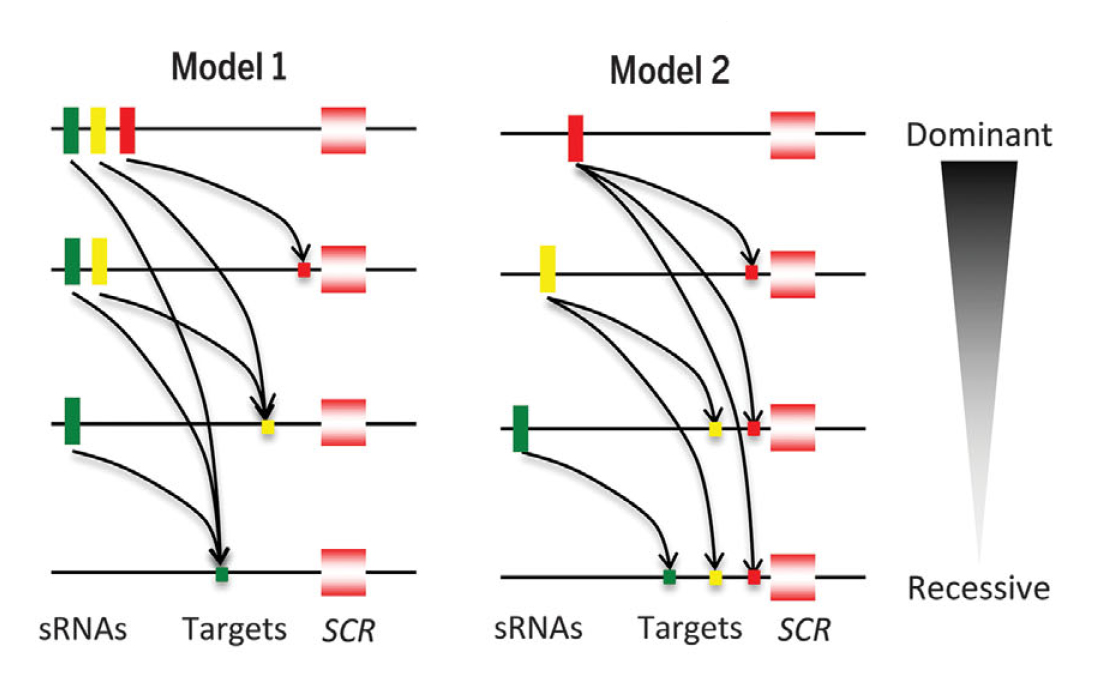
The way an allele becomes dominant over another allele is simple: a small RNA encoded by the first allele recognises a specific sequence on the second allele and blocks its expression. However, there are dozens of self-incompatible alleles in natural populations. How can a small RNA-target mechanism control dominant and recessive relationships between hundreds of possible allele pairs, and how did it develop? This is where the recent research published in the 5 December 2014 issue of Science comes into play. Researchers with a range of skills from diverse fields – from bioinformatics to genetic transformation and phylogenetic methodologies –all worked together to provide a nearly complete explanation to this complex question (see Chapter Three).
(1) Y. Tarutani et al., Nature 466, 983–986 (2010).